Probably the most important thing to get great results out of Claude Code, give Claude a way to verify its work. If Claude has that feedback loop, it will 2-3x the quality of the final result. Claude tests every single change I land.
That is the single piece of advice Boris Cherny repeats more than any other across podcasts, Twitter threads, and launch posts.
Most users invest their first weekend with Claude Code learning prompt engineering tricks. The team that actually built Claude Code thinks you should invest that weekend in verification instead. The prompt matters, but the feedback loop matters more, by a wide margin.
The Quote Boris Cherny Won't Stop Repeating
Boris first posted this on January 2, 2026. It is short, blunt, and specific. A 2-3x quality improvement is not a vague claim. It is a number that suggests the team has measured this internally and converged on it. The phrasing is also telling: not most changes, but every change.
Three and a half months later, on April 16, 2026, Boris repeated essentially the same advice when Opus 4.7 launched. When someone leading a product says the same thing twice in the same quarter, they are not filling time. They are signaling that this is the lever, and that most users still are not pulling it.
Cat Wu, the product lead on Claude Code, posted alongside the Opus 4.7 launch saying the same thing in slightly different words.
Tell the model how to verify its changes. Put your testing workflow in your claude.md, or add a /verify-app skill. Opus 4.7 is better at verifying its work, and it's helpful to share any local dev tips that are hard to discover.
That post is worth reading in full because Cat names the specific files where verification context belongs.
The biggest quality jump in Claude Code is not a better prompt, it's a tighter feedback loop. The team measures this as a 2-3x improvement and treats it as the single most important setup decision.
The implication is uncomfortable for people who have spent months refining elaborate prompt templates. The team is not saying prompts do not matter. They are saying that if you have an hour to invest in Claude Code quality, you should spend most of it on the verification side of the loop, not the instruction side. The reason becomes clearer once you see Thariq Shihipar's hierarchy.
Thariq's Verification Hierarchy
Thariq Shihipar, who works on Claude Code, posted a verification ranking on April 8, 2026 that has become the unofficial mental model the team uses internally. His ordering, from most to least valuable, is rules-based first, then visual, then LLM-as-judge. Each tier is dramatically more expensive than the one below it, and dramatically less reliable.
Rules-based verification means unit tests, linters, type checkers, schema validators, and anything else that produces a deterministic pass or fail in milliseconds. It is the bedrock. A type checker catches an entire class of bugs that no amount of LLM reasoning would catch reliably, and it does so for essentially zero cost. If your project does not have a fast test suite that Claude Code can run after every edit, that is the first investment to make. Everything else compounds on top of it.
Visual verification comes next. Screenshots, Playwright runs, visual diffs against reference images. Thariq specifically calls out the value of "Storybook-like environments that record video proof" of a component working. This tier matters because some bugs only manifest visually, a layout shift, a misaligned button, a color contrast failure. A unit test cannot see those. But visual checks are slower and more expensive, so they sit above the rules tier, not below it.
LLM-as-judge sits at the top of the pyramid because it is the slowest and least reliable mode of verification.
It's very easy to spend a lot of tokens on open ended verification that doesn't make your output better.
A judge model reading code and asking "is this good?" rarely catches what a typechecker would catch in 50 milliseconds. Use it for the genuinely subjective questions that no rule can express, and only after the lower tiers have run clean.
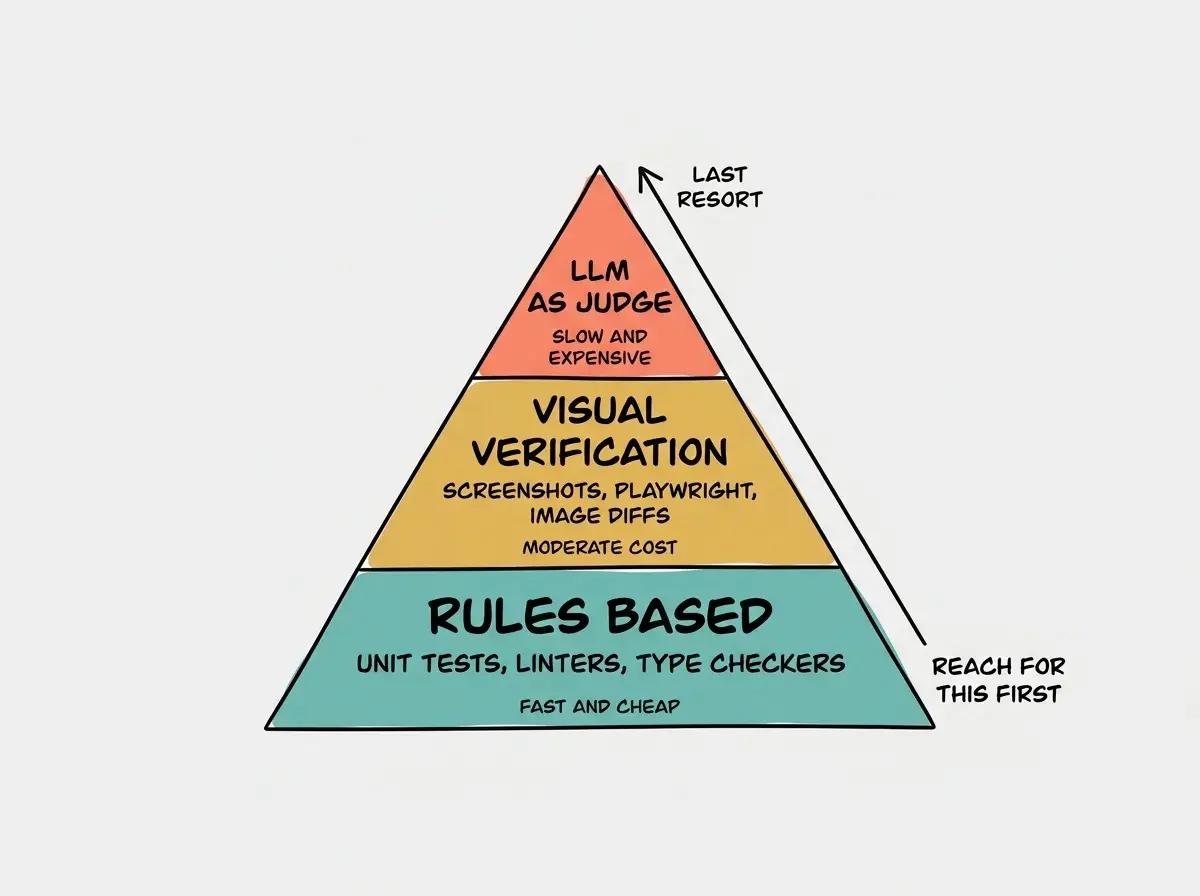
The pyramid shape is not arbitrary. The bottom tier should run constantly, on every save, on every commit, on every CI run. The middle tier should run when the bottom tier passes, gated by changes that could affect visual output. The top tier should run rarely and only when nothing else can answer the question. Reversing this order is the most common mistake, and it is also the most expensive one.
Put Your Verification In CLAUDE.md
Cat Wu's framing is the practical handoff between the principle and the implementation.
Put your testing workflow in your claude.md, or add a /verify-app skill.
Concretely, that means a Commands section in your CLAUDE.md that lists the exact invocation for your test suite, your linter, your type checker, and your dev server. Not "use the test command" but npm run test -- --run. Not "check the dev server" but "the dev server runs at localhost:3000 and logs to dev.log, a passing build prints READY in green."
The skill option goes further. A /verify-app skill is a markdown file in .claude/skills/ that defines the full verification pipeline. It can spin up the dev server if needed, run the test suite, capture a screenshot of the main page, diff it against the reference image, and report a single pass or fail. When Claude Code finishes a change, it invokes the skill, reads the output, and either declares success or iterates. The skill captures the team's tribal knowledge about what counts as a working build, in one place that every session can read.
Sid Bidasaria, who works on Claude Code, has noted on the MLOps Community podcast that roughly 90 percent of the codebase is Claude-written, and tests are closer to 100 percent.
Unit tests and smaller units of tests will be probably the shortest path to verification success.
If your project does not yet have a fast unit test suite, asking Claude Code to write one is itself a high-leverage first task. The tests do not have to be perfect. They have to be fast and they have to fail loudly when something breaks.
We're publishing a deep-dive series on how the Claude Code team actually ships.
Browse our Claude Code coverageThere is a deeper point hiding inside Cat's tweet about local dev tips that are hard to discover. Every project has knowledge that lives in someone's head, the dev server takes 30 seconds to come up, the test suite needs a clean database, the linter has one rule that always trips up first-time contributors. Writing that knowledge into CLAUDE.md is not just helpful for Claude Code. It is the kind of onboarding document every project should have anyway. Verification setup is a forcing function for documenting your project the way you should have already documented it.
Stop Hooks, Let Claude Keep Going Until It Verifies
Once verification is wired up, the next move is letting Claude run the loop autonomously. On the Every podcast, Boris put it bluntly.
If the tests don't pass, keep going. Essentially you can just make the model keep going.
Stop hooks are the mechanism. They intercept Claude Code's attempt to end a turn, run a check, and if the check fails, they tell Claude to keep working.
The result is an autonomous verification loop. Claude writes code, the test suite runs, the test suite fails, the stop hook fires, Claude reads the failure output, Claude fixes the issue, the suite runs again. No human in the inner loop. Boris posted on December 27, 2025 on Threads that Claude consistently runs for minutes, hours, and days at a time using exactly this pattern. The duration is the giveaway. You cannot run an agent for hours if you have to babysit it. You can only do that when the verification loop is tight enough to catch its own mistakes.
Thariq frames the same idea more abstractly.
One of my favorite concepts is the idea of defining outcomes where the agent will work until the rubric is satisfied.
The rubric is the verification suite. The agent's job is to make the rubric pass, not to produce output that looks correct. This is a fundamentally different framing from "write code and stop." It is closer to "satisfy this contract, by any reasonable path, and tell me when you are done."
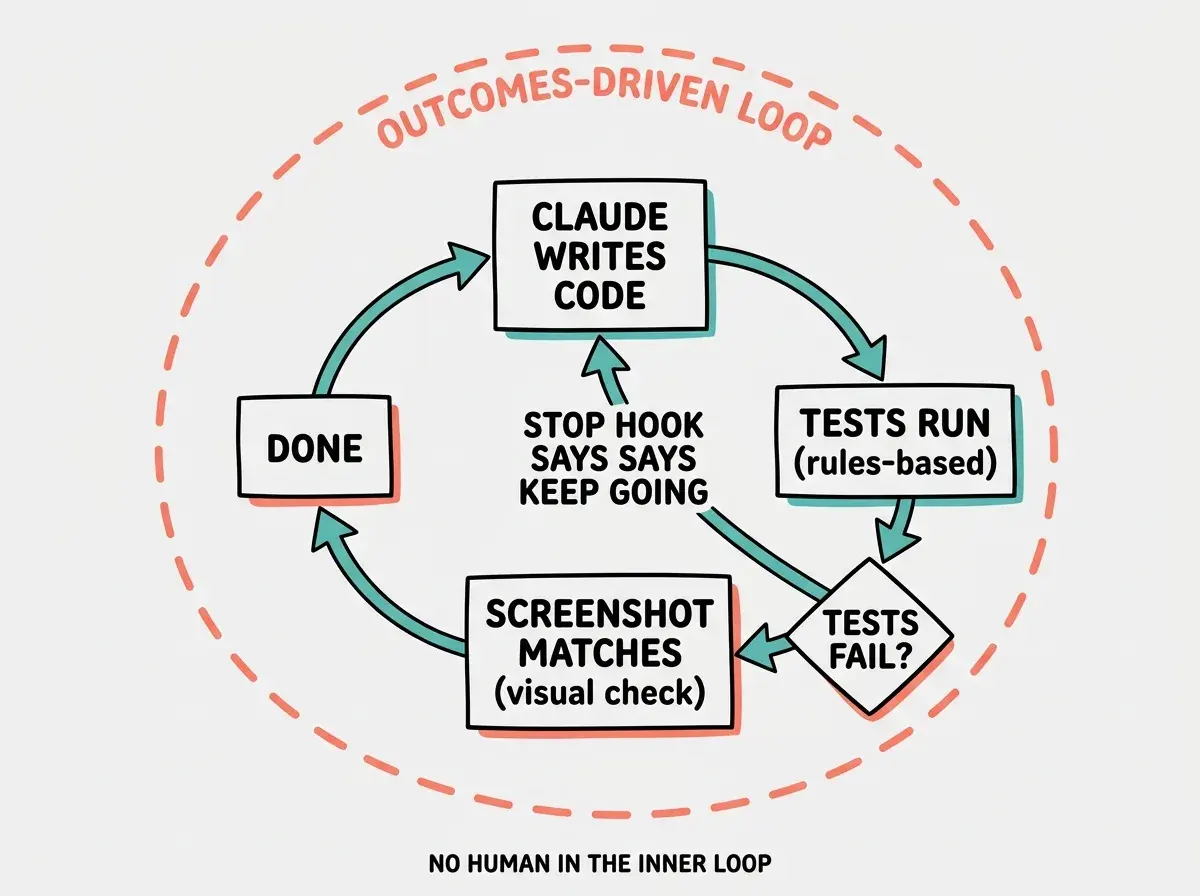
The combination of a fast verification suite and stop hooks is what makes truly long-running agents possible. Without verification, a stop hook just lets the model loop on the wrong target. Without stop hooks, verification just becomes a thing humans manually check. Together, they form the closed loop the team uses in production. Erik Schluntz, who has worked on the agent infrastructure side, made a related point about tool design.
You need to iterate on tools rather than just a prompt.
The verification skill is exactly the kind of tool he is describing. You refine the skill over weeks, not the prompt over hours.
Reaching for LLM-as-judge first. It's the slowest and most expensive verification mode, and it often misses the bugs that a 50-millisecond unit test would catch. Thariq's hierarchy exists because the team has wasted plenty of tokens on this exact mistake.
The pattern most beginners fall into is asking a second Claude invocation to review the first one's output. It feels rigorous because there is a critique step. It is actually expensive, slow, and far less accurate than running the tests the project already has. If you find yourself building a judge before you have a test runner wired up, stop and build the test runner first.
Setting Up Verification In Your Project Today
The practical setup takes less than an hour. Start with the Commands section of your CLAUDE.md, list the exact invocation for your test suite, your type checker, your linter, and your dev server, and document what a passing run looks like. Next, edit .claude/settings.json to add npm test, npm run lint, and npm run typecheck to the allowlist so Claude Code can run them autonomously without prompting you for permission every time. That single change converts verification from a manual checkpoint into a background activity Claude can perform freely.
Then create a verify-app skill in .claude/skills/verify-app.md. The skill should run the test suite, capture the output, run the type checker, capture that output, and report a single structured result. If your app has a UI, add a Playwright check or a screenshot diff to the same skill. The skill becomes the single command Claude invokes after every meaningful change. Erik Schluntz's observation about browser tooling applies here directly.
With computer use, just give the thing a browser logged into what you want, it's going to work immediately.
The same logic applies to verification: give Claude a single command that exercises the full app and it will use that command as its source of truth.
Once the skill exists, add a stop hook in .claude/settings.json that runs verify-app before allowing Claude Code to end its turn. The hook reads the output. If verification fails, the hook returns a non-zero exit code and a message telling Claude to keep working. If verification passes, the turn ends cleanly. This is the moment the loop closes. From this point forward, every change Claude lands has been verified by the same suite, the same way, before it ever reaches you.
What This Means For You
- If you're a founder: Investing in tests pays dividends in agent quality, not just human quality. A test suite that catches regressions in CI also catches them in Claude's inner loop, which means Claude ships better code faster. Verification is the highest-leverage technical debt to pay down right now.
- If you're changing careers: The verify-then-build loop is faster to learn than prompt-engineering tricks. Spend your first week setting up CLAUDE.md, a verify skill, and a stop hook, and you will outperform people who have been writing clever prompts for months.
- If you're a student: Read Thariq's verification post and copy his hierarchy as your default mental model. Rules-based first, visual second, LLM-as-judge last. Apply it to every coding agent you ever build, not just Claude Code.
Three steps to your first verify-app skill, done in under an hour.
See the team's playbook