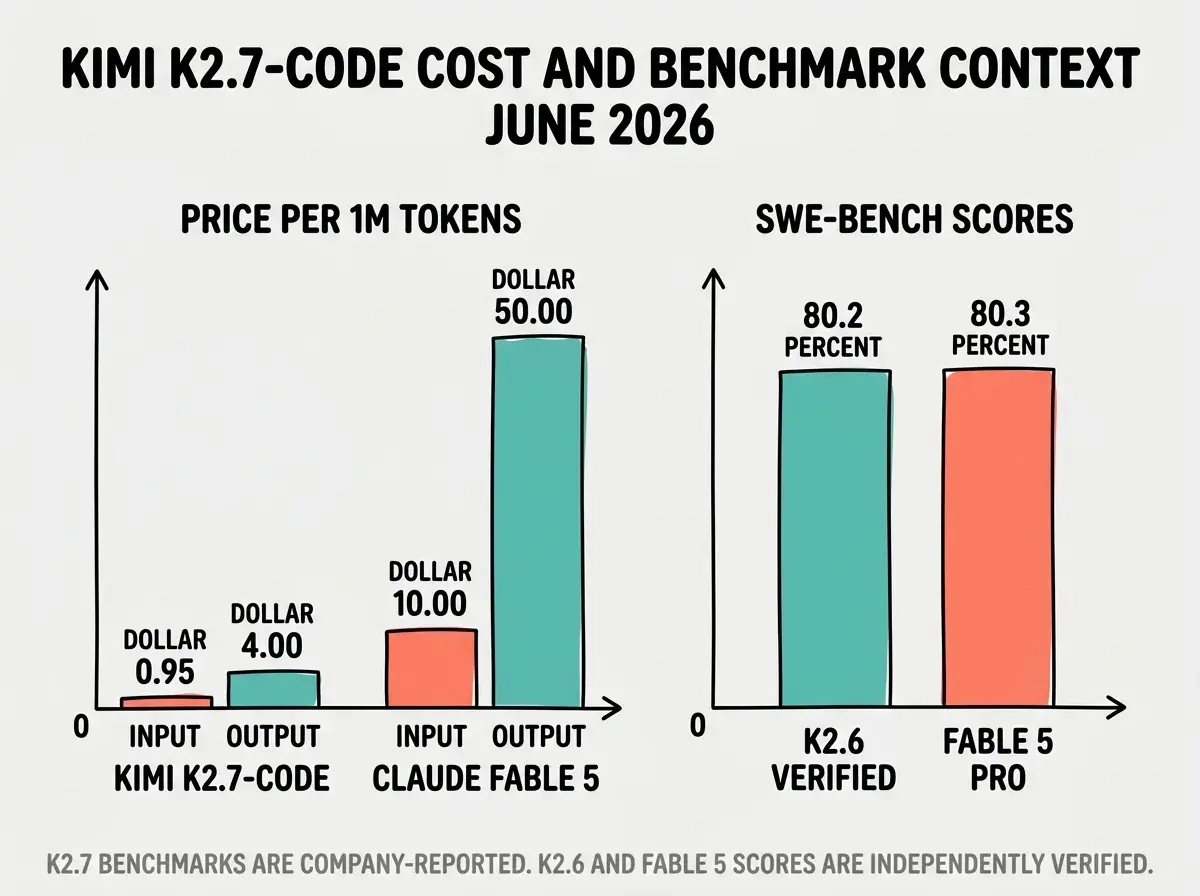
Moonshot AI released Kimi K2.7-Code on June 12 under a Modified MIT license. It is a 1-trillion-parameter Mixture-of-Experts coding model with a 256K token context window, available immediately on the Kimi API at $0.95 per million input tokens and $4.00 per million output tokens. That price is roughly five times cheaper on input and twelve times cheaper on output than Claude Fable 5.
The context for why this matters starts one version back. Kimi K2.6, released in April 2026, independently scored 80.2% on SWE-Bench Verified and 58.6% on SWE-Bench Pro. Those numbers were confirmed by third-party evaluators and placed K2.6 in direct competition with frontier models at a fraction of the cost. K2.7-Code builds on that foundation with a reported 30% reduction in reasoning token consumption and higher scores on Moonshot's own coding benchmarks. The independent verification for K2.7 benchmarks has not yet landed, but the underlying architecture and the track record of K2.6 make the release worth paying attention to now.
Why Does the K2 Series Track Record Matter for Vibecoders
The K2 series is not a newcomer making unverifiable claims. Kimi K2.5 is the model Cursor retrained to build Composer 2.5, the engine that scored 79.8% on SWE-Bench Multilingual and became Cursor's default agentic model in May 2026. K2.6 then cleared 80.2% on SWE-Bench Verified in independent testing by third-party evaluators, ranking sixth among 67 models on Code Arena WebDev (blind pairwise evaluation, as of April 2026). The K2 architecture has now been independently tested at two successive versions and delivered on its benchmark claims both times.
K2.7-Code is the third iteration in roughly eight weeks. The 30% reduction in reasoning token consumption is the most actionable change: it means a given agentic task on K2.7 should consume materially fewer tokens than on K2.6 for the same quality output, which is a direct cost reduction on top of the already low baseline pricing.
Kimi K2.7-Code is live on the Kimi API and OpenRouter (model ID moonshotai/kimi-k2.7-code) as of June 12, 2026. The price is $0.95 per million input tokens and $4.00 per million output tokens. The MIT license permits commercial use with attribution. You can also access K2.7-Code through the Kimi Code CLI, which is a free, open-source terminal agent with MCP support and VS Code integration, built on the same model weights.
Moonshot has also published K2.7-Code to Hugging Face for self-hosting. The full weights are available under the Modified MIT License, which allows commercial deployment. This makes K2.7-Code the most capable openly licensed 1-trillion-parameter coding model available as of this writing, if you have the infrastructure to run it. The practical path for most vibecoders is the hosted API rather than self-hosting; a 1T MoE model with 32B active parameters requires significant GPU resources. But the license means that derivative models, fine-tunes, and custom wrappers are legal, which matters for the open-source tooling ecosystem around it.
What Changed Between K2.6 and K2.7-Code
Kimi K2.7-Code uses a nearly identical MoE architecture to K2.6: 384 experts, 8 selected per token (plus 1 shared), 61 layers with one dense layer, Multi-head Latent Attention, and SwiGLU feed-forward layers. A MoonViT vision encoder adds 400M parameters for image and video input. The same 256K context window carries over. What changed is training: K2.7-Code was trained specifically to reduce the number of reasoning tokens required per task while improving task accuracy.
The 30% reasoning token reduction is the kind of efficiency gain that compounds across an agentic session. A typical multi-file refactor in Claude Code might touch 15 to 20 tool calls, each with a reasoning phase before the action. If each reasoning phase uses 30% fewer tokens, that is a meaningful reduction in session cost even before factoring in the lower per-token price.
Moonshot also reports that K2.7-Code scores 81.1% on MCPMark Verified, their benchmark measuring correct Model Context Protocol tool invocation, compared to Claude Opus 4.8 at 76.4% on the same test. MCPMark is Moonshot's own benchmark, not an independent suite, so treat this number as directionally interesting rather than definitively settled. The MCP tool-use angle is nonetheless the right thing to measure for agentic coding: tool call reliability is where coding agents fail in practice, not in abstract reasoning tasks.
How Do You Use Kimi K2.7-Code Today
There are three practical access paths, each suited to a different situation.
Kimi Platform API. Sign up at kimi.com, add API credits, and call https://api.moonshot.ai/v1 with model ID kimi-k2.7-code. The interface is OpenAI-compatible, so existing SDK integrations drop in with a base URL change and no other modifications. This is the most direct path and gives you the lowest latency since you are hitting Moonshot's own servers.
OpenRouter. If you already use OpenRouter to route between models, K2.7-Code is available at moonshotai/kimi-k2.7-code. OpenRouter adds a small routing markup but simplifies multi-model setups where you want to switch between K2.7, Claude Fable 5, and other providers in the same application.
Kimi Code CLI. Moonshot's open-source terminal coding agent, built on the same model weights, runs on the same K2 inference backend. The CLI is available under Apache 2.0 with more than 6,400 GitHub stars. It supports MCP tools, VS Code and Cursor extension integration, and autonomous planning with the same loop structure as Claude Code. If you want a fully self-contained agentic setup that runs K2.7-Code without any Claude Code dependencies, Kimi Code CLI is the current option.
The Vibe Coder Blog covers what vibecoders need to act on across Claude Code, Cursor, and the broader tooling ecosystem.
Browse All PostsThe Claude Code path, which involves pointing ANTHROPIC_BASE_URL at the Kimi API, worked cleanly with K2.5 and K2.6. K2.7-Code should behave the same way given its OpenAI-compatible API surface. For teams that want to run Claude Code's agent harness with K2.7-Code as the underlying model, the swap is a two-environment-variable change (ANTHROPIC_BASE_URL and ANTHROPIC_API_KEY). This is not officially supported by Anthropic, but the K2 series has been stable enough for this use in practice.
What Should Vibecoders Know About the Benchmark Caveats
K2.7-Code launched with only Moonshot's proprietary benchmarks: Kimi Code Bench v2, Program Bench, MLS Bench Lite, MCPMark Verified, and MCP Atlas. None of these are standard public suites. SWE-Bench Verified, SWE-Bench Pro, LiveCodeBench, and other independent evaluations have not yet been published for K2.7-Code as of June 14.
This is a genuine gap. The claims of +21.8% on Kimi Code Bench v2 over K2.6 and +31.5% on MLS Bench Lite are interesting, but proprietary benchmarks designed by the model creator are not reliable predictors of real-world performance. The correct way to read K2.7-Code right now is through the lens of what K2.6 established independently, plus the reasonable expectation that a model trained with 30% efficiency improvements on a proven architecture will be at least as good.

The risk in skipping the caveats is building a workflow around K2.7-Code's claimed performance, then finding when independent scores arrive that real-world performance is lower on the tasks you care about. The safer approach is to run K2.7-Code on your own tasks for a week via the API, compare output quality to K2.6 or your current model, and make your own determination before making it a default.
Treating any model's proprietary benchmark scores as a reliable predictor of performance on your actual tasks. Moonshot's Kimi Code Bench v2, Program Bench, and MLS Bench Lite are designed by Moonshot and measure what Moonshot chose to measure. Independent evaluation on SWE-Bench Verified and SWE-Bench Pro will appear within weeks and give a much more reliable signal. The right move now is to run K2.7-Code on a concrete sample of your own work before committing to it as a default model.
The pricing argument does not depend on benchmarks at all. If K2.7-Code performs comparably to K2.6 at 30% fewer reasoning tokens, you get the same output quality for materially lower token cost. That is enough reason to test it this week while the independent numbers are pending.
What Does This Mean for Your Vibe Coding Workflow
The K2.7-Code release is most immediately relevant to three types of vibecoders.
Cost-sensitive solo builders running long agentic sessions where the token bill is the main constraint. At $0.95/$4.00, K2.7-Code makes frontier-class agentic sessions economically sustainable at a pace and scale that would be prohibitively expensive at Claude Fable 5 pricing.
Teams building agents or apps on top of a model API. The MIT license matters here because it removes the per-seat restrictions of closed-model API terms. You can build and ship a product on top of K2.7-Code without worrying about the downstream licensing implications that come with models like Fable 5. Attribution is required; restrictions on the model itself are minimal.
Open-source tooling builders. K2.7-Code being publicly licensed means you can fine-tune it, distill from it, and redistribute modified versions. The Kimi Code CLI is already showing what this makes possible at the application layer. Expect this to generate fine-tuned variants optimized for specific domains, languages, or agent frameworks over the next few months.
The one caveat that applies to all three groups: wait for independent SWE-Bench scores before making K2.7-Code your sole production model. The K2 series has earned trust over the past two versions, but trust is not a substitute for verification on the tasks you actually care about.
The Kimi K2.7-Code weights are on Hugging Face and the model is available on OpenRouter today. Independent benchmark results will provide a clearer picture of where it sits in the current landscape. In the meantime, the combination of verified K2.6 performance, a price point five times below Fable 5, and a genuinely open license makes K2.7-Code worth running on your own tasks this week.
The Vibe Coder Blog tracks what builders need to know about AI coding tools, models, and costs.
Read More