Imagine every public library in the country had to send every book request to a single warehouse in Virginia. You drive to your local branch, ask for a book, and the librarian says "let me fax the central warehouse." Twenty minutes later, your book arrives. That is how most databases work today. Your app sends a query across the internet to a single-region database, waits for the round trip, and then responds to the user.
Turso edge SQLite flips this model. It puts a copy of your database in every city, like a library system with local branches stocked with all the books people actually read. Readers walk in, grab what they need, and walk out. No fax machine. No waiting. That is what embedded replicas do for your application's read latency.
With 92% of developers using AI tools daily to ship faster, the database layer is increasingly the bottleneck that tooling alone cannot fix. Your AI assistant can generate a perfect API route in seconds, but if that route queries a database 200ms away from your user, the experience suffers. Turso solves this at the infrastructure level.
What Turso Actually Is
Turso is a managed database service built on libSQL, an open-source fork of SQLite maintained by the Turso team. The fork adds features that SQLite intentionally leaves out: HTTP-based access, server mode, write-ahead log (WAL) replication, and the ability to run as a network-accessible service rather than just an embedded file.
Think of libSQL as the upgraded engine inside Turso. Regular SQLite is a single-file database designed for one process. libSQL keeps everything good about SQLite (the query compatibility, the simplicity, the battle-tested reliability) and adds the networking and replication layers needed for production multi-region deployments.
The key innovation is that libSQL replicas are real SQLite databases on disk. They are not caches. They are not proxies. They are full SQLite files that your application reads from directly, with replication happening asynchronously from a primary instance. Going back to the library analogy, each branch holds real physical books, not photocopied summaries.
Embedded Replicas and Why They Matter
Embedded replicas are the feature that separates Turso from every other managed database. Here is how they work.
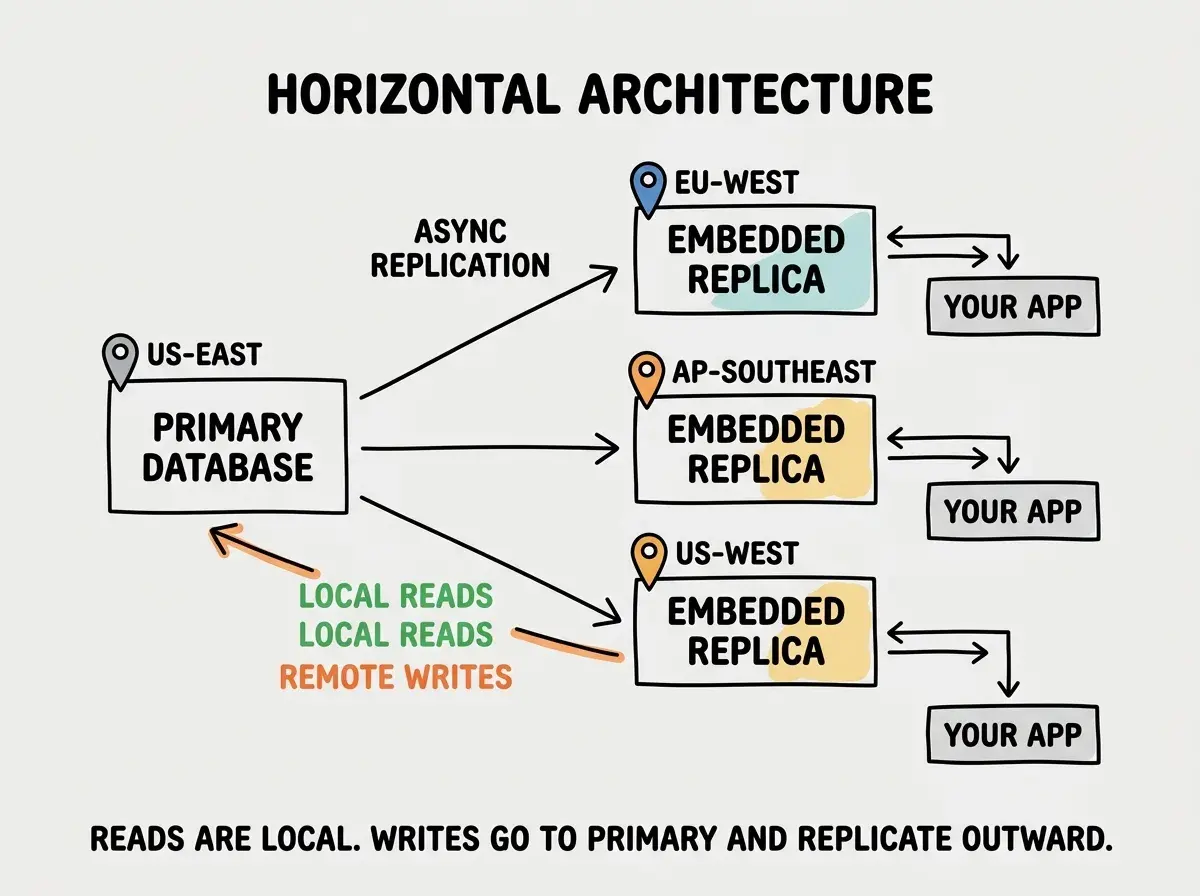
Your application bundles a local SQLite file as part of its deployment. When the app starts, Turso's client library syncs this local file with the primary database. Reads happen against the local file with zero network latency. Writes go to the primary database over the network, then replicate back to all embedded replicas.
import { createClient } from '@libsql/client';
const client = createClient({
url: 'file:local-replica.db',
syncUrl: process.env.TURSO_DATABASE_URL,
authToken: process.env.TURSO_AUTH_TOKEN,
syncInterval: 60, // sync every 60 seconds
});
// This read hits the LOCAL file, not the network
const users = await client.execute('SELECT * FROM users WHERE active = 1');
// This write goes to the primary, then replicates back
await client.execute({
sql: 'INSERT INTO users (name, email) VALUES (?, ?)',
args: ['Alice', 'alice@example.com'],
});
// Force a manual sync when you need fresh data immediately
await client.sync();
The read in that example completes in microseconds, not milliseconds. Your local branch library already has the book on the shelf. For read-heavy applications (which is most applications), this changes the performance profile entirely.
Multi-Region Replication Without the Headache
Traditional multi-region database setups require you to configure leader election, handle split-brain scenarios, manage connection strings per region, and pray that your replication lag does not cause stale reads. Turso handles all of this with a single CLI command.
# Create a database
turso db create my-app-db
# Add replicas in specific regions
turso db replicate my-app-db --location lhr # London
turso db replicate my-app-db --location nrt # Tokyo
turso db replicate my-app-db --location gru # São Paulo
# List all locations
turso db show my-app-db --locations
Your application connects to a single URL, and Turso routes reads to the nearest replica automatically. The local branch library system handles the logistics. You just hand readers a library card and let the system figure out which branch is closest.
This simplicity matters because multi-region is traditionally an "enterprise architecture" problem. With Turso, a solo developer deploying to Cloudflare Workers or Fly.io gets global read performance without a DevOps team.
Drizzle ORM Integration
Drizzle ORM has first-class support for Turso through the @libsql/client driver. The integration is clean and feels native to the Drizzle ecosystem.
import { drizzle } from 'drizzle-orm/libsql';
import { createClient } from '@libsql/client';
import { users } from './schema';
import { eq } from 'drizzle-orm';
const client = createClient({
url: 'file:local-replica.db',
syncUrl: process.env.TURSO_DATABASE_URL,
authToken: process.env.TURSO_AUTH_TOKEN,
});
const db = drizzle(client);
// Type-safe queries with embedded replica performance
const activeUsers = await db
.select()
.from(users)
.where(eq(users.active, true));
You get Drizzle's type safety, its SQL-like query builder, and its tiny bundle size, combined with Turso's embedded replica reads. For edge deployments on Cloudflare Workers where bundle size matters, this combination is particularly strong. Drizzle's ~50 KB client plus libSQL's lightweight driver fits comfortably within Worker size limits.
The schema definition works exactly like any other Drizzle SQLite setup, so migrating an existing Drizzle + SQLite project to Turso requires changing only the client initialization.
Turso edge SQLite is not just another managed database. The embedded replica model fundamentally changes your read performance profile by eliminating network round trips entirely. For read-heavy applications serving users globally, this is a different category of solution compared to traditional centralized databases with connection pooling.
When Turso Beats Supabase and Neon
Supabase and Neon are excellent databases, but they solve a different problem. Both are centralized PostgreSQL services. They run in one region (or a few regions with read replicas in Neon's case), and your application connects to them over the network for every query.
Edge-first applications. If your app runs on Cloudflare Workers, Deno Deploy, or Vercel Edge Functions, Turso's embedded replicas give you local reads with no network hop. Supabase and Neon both require a network round trip for every query, even with connection pooling. When your Worker runs in Sydney and your Supabase instance is in Virginia, that is 150-200ms of latency on every database call.
Embedded use cases. Turso works as an embedded database in desktop apps, mobile apps, and CLI tools. The libSQL client can operate in local-only mode, sync mode, or remote-only mode. Supabase and Neon are server-only. If you need a database that ships with your application binary, Turso is the natural fit.
Read-heavy workloads with global users. A content platform, a documentation site, an analytics dashboard, a product catalog. Any application where reads vastly outnumber writes benefits disproportionately from embedded replicas. Every read is a local file operation instead of a network request.
Where Supabase and Neon still win. Complex relational queries, stored procedures, full-text search with PostgreSQL's advanced features, real-time subscriptions (Supabase), branching workflows (Neon), and the massive PostgreSQL extension ecosystem. If your app needs PostGIS, pg_vector, or advanced JSON operations, PostgreSQL is the better foundation.
Choosing Turso for write-heavy workloads expecting the same performance gains as read-heavy ones. All writes still go to the primary database over the network. Embedded replicas only accelerate reads. If your application does more writes than reads (real-time chat, high-frequency logging, IoT data ingestion), you will not see the latency improvements that make Turso compelling. Evaluate your read/write ratio before committing.
Limitations Worth Knowing
Turso is SQLite under the hood, which means SQLite's constraints apply. You get a single-writer model. Concurrent writes queue behind each other rather than running in parallel like PostgreSQL. For most web applications this is fine because reads dominate, but write-heavy workloads will hit this ceiling.
The SQLite type system is more permissive than PostgreSQL's. There are no native JSON columns, no array types, no ENUMs at the database level. Drizzle adds type safety at the application layer, but the database itself will not reject a string in an integer column the way PostgreSQL would.
Replication lag exists. Embedded replicas sync on an interval you configure (or on manual sync calls). If your application writes a record and immediately reads it from the replica, the read might return stale data. You need to either sync manually after critical writes or read directly from the primary for consistency-sensitive operations.
The ecosystem is younger than PostgreSQL-based alternatives. Fewer tutorials, fewer Stack Overflow answers, and fewer battle-tested patterns in production. The libSQL project is actively maintained and the community is growing, but you will encounter rough edges that PostgreSQL tools smoothed out years ago.
See how Turso compares to other tools in the edge database landscape.
Explore edge toolsPricing and the Free Tier
Turso's free tier is generous for side projects and small apps. You get 9 GB of total storage, 500 databases, and unlimited read replicas. The Scaler plan at $29/month adds more storage and higher row limits. For most indie developers and small teams, the free tier covers initial development and early production use.
The pricing model charges based on rows read and rows written rather than compute time or connection count. This is more predictable than Neon's compute-hour billing but can surprise you if your application scans large tables frequently. Add appropriate indexes and avoid SELECT * on large tables to keep row-read counts reasonable.
Compared to Supabase's free tier (500 MB storage, one project) and Neon's free tier (512 MB storage, one project), Turso gives you significantly more room to experiment with multi-tenant architectures where each tenant gets their own database.

What This Means For You
Turso edge SQLite fills a specific and growing niche. As more applications deploy to edge runtimes and more developers build globally distributed apps, the "central library warehouse" model of traditional databases becomes the performance bottleneck.
If your application is read-heavy, globally distributed, and running on edge infrastructure, Turso's embedded replica model is not just an optimization. It is a fundamentally different architecture that eliminates network latency from your most common database operations. The local branch library is open, the books are on the shelf, and your users do not have to wait.
For write-heavy applications, complex relational queries, or teams deeply invested in the PostgreSQL ecosystem, Supabase and Neon remain stronger choices. But if you have been struggling with database latency on edge deployments, Turso is worth a serious evaluation.
Learn the full stack for building and deploying modern web applications.
Start building