An AI deployment failure at Amazon took down services for millions of users after an automated deployment pipeline pushed configuration changes that looked correct in isolation but caused cascading failures across dependent systems. The incident reveals what happens when AI-assisted tooling optimizes for local correctness without accounting for system-wide dependencies, and why deployment guardrails remain non-negotiable.
What Happened at Amazon
Amazon operates one of the most sophisticated deployment infrastructures in the world. Their internal tooling manages millions of deployments per year across thousands of microservices. To handle this scale, Amazon has increasingly integrated AI-assisted tooling into their deployment pipeline, using models to suggest configuration optimizations and automate routine infrastructure changes.
During a routine deployment cycle, the AI-assisted system suggested configuration changes to a core networking service. The changes targeted load balancer routing rules and connection pool settings. Each individual change appeared reasonable. The AI had analyzed historical performance data and identified suboptimal configurations. It recommended adjustments that would improve latency and reduce resource consumption.
The problem was that these changes interacted with each other and with downstream services in ways the AI model did not predict. The updated routing rules shifted traffic patterns across availability zones. The modified connection pool settings reduced the number of available connections to a database cluster. Independently, either change would have been absorbed by the system's redundancy. Together, they created a bottleneck that cascaded through dependent services within minutes.
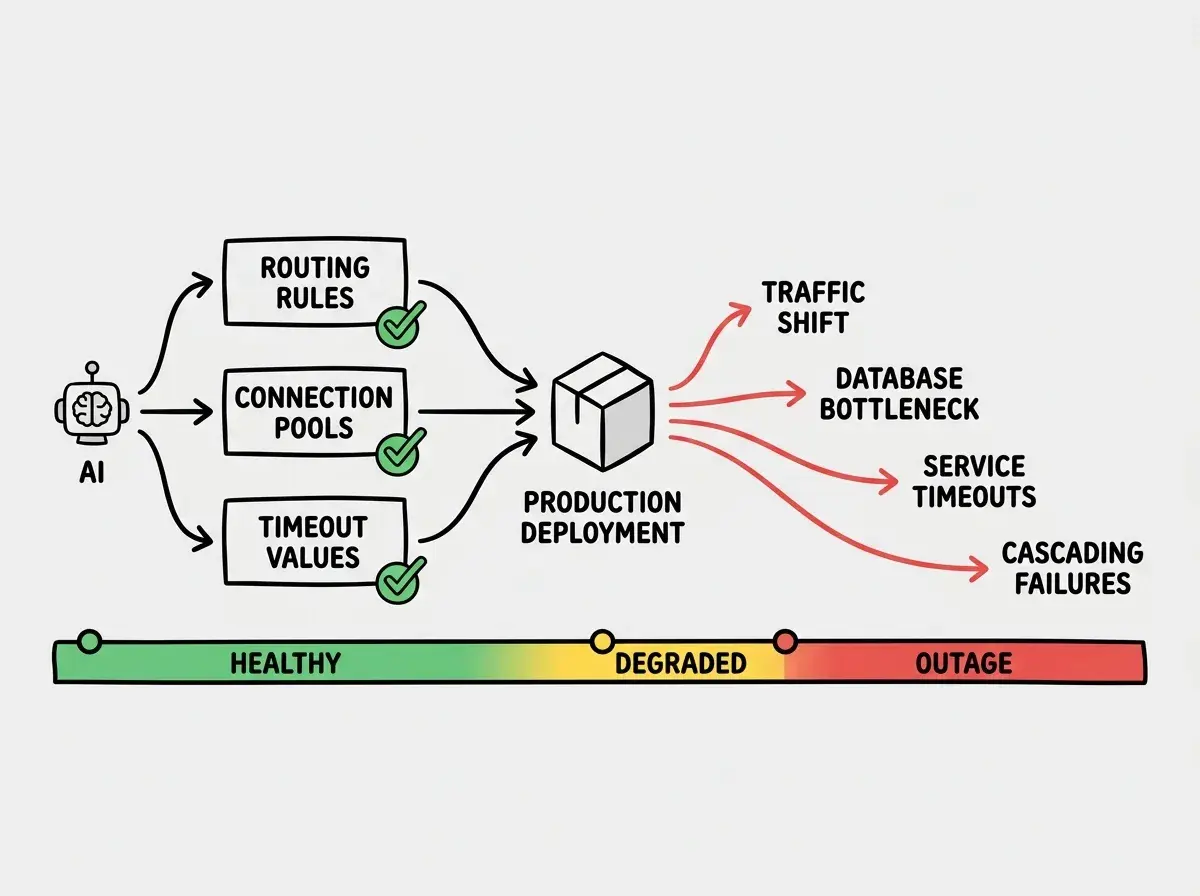
The database cluster hit its connection limit. Services that depended on that cluster started timing out. Those timeouts triggered retry storms from upstream services, which amplified the load. Within fifteen minutes, the failure had propagated across multiple service boundaries, affecting S3, Lambda, and several high-traffic consumer-facing applications.
Amazon's monitoring detected the degradation quickly. But the automated rollback mechanisms were not configured to treat AI-suggested changes as a single atomic deployment. The system rolled back individual changes sequentially rather than reverting the entire batch, which temporarily made things worse before engineers intervened manually.
Why AI-Suggested Changes Create Unique Risks
Traditional deployment failures typically involve a single bad change. A developer introduces a bug, a configuration value gets set incorrectly, a dependency breaks. The blast radius is usually predictable because humans tend to make one change at a time and can reason about its impact.
AI-assisted deployment tools operate differently. They analyze system-wide telemetry and generate multiple optimization recommendations simultaneously. Each recommendation is evaluated against historical data and validated individually. But the validation step almost never accounts for the interaction effects between simultaneous changes.
This is the fundamental gap. The AI optimizes each parameter independently, like a chess engine evaluating individual moves without considering the full board position. A connection pool reduction looks fine in isolation. A routing rule change looks fine in isolation. Deploy both at the same time, and the system enters a state that neither change was tested against.
Amazon's deployment AI was not making an error in the traditional sense. Every suggestion was locally correct. The routing changes would have improved latency if deployed alone. The connection pool changes would have reduced resource waste if deployed alone. The failure was in the deployment process that allowed multiple AI-suggested changes to ship together without modeling their combined effect.
AI deployment tools optimize for local correctness, not system-wide safety. Every AI-suggested infrastructure change must be treated as a hypothesis that needs validation in context, not a recommendation that can be applied directly. The deployment pipeline, not the AI, is responsible for ensuring that changes do not interact in destructive ways. When multiple AI suggestions ship together, the risk is not additive. It is multiplicative.
The Cascading Failure Pattern
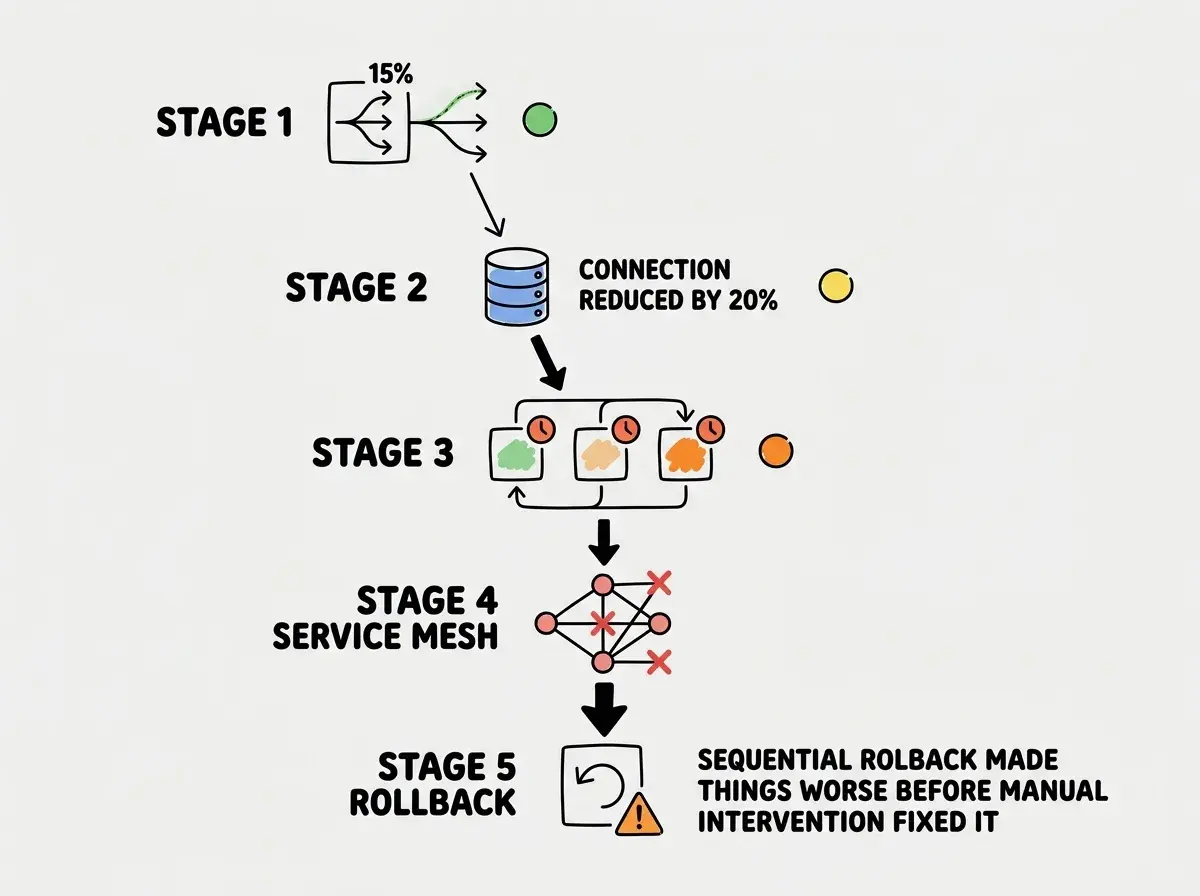
The Amazon outage followed a pattern that infrastructure engineers call a "cascade amplification loop." Understanding this pattern is critical because it explains why small configuration changes can produce outsized failures.
Stage one, the trigger. The AI-suggested routing changes shifted approximately 15% of traffic from one availability zone to another. This was within normal variance and did not trigger any alerts on its own.
Stage two, the bottleneck. The connection pool reduction, deployed simultaneously, lowered the maximum connections to the database cluster by 20%. Under normal traffic distribution, this would have been fine. But with the shifted traffic pattern, one availability zone was now receiving more requests than its reduced connection pool could handle.
Stage three, the timeout cascade. Services waiting for database connections started timing out. Their callers received errors and retried. Each retry consumed another connection slot, further starving the pool. The retry storm turned a bottleneck into a complete blockage within minutes.
Stage four, the propagation. Services that depended on the now-failing service began failing themselves. Health checks started failing across the service mesh. Load balancers began routing traffic away from "unhealthy" instances, concentrating load on the remaining healthy instances, which then became unhealthy under the increased load.
Stage five, the rollback complication. Automated rollback attempted to revert changes one at a time. Rolling back the routing change first (without simultaneously rolling back the connection pool change) created a different traffic pattern that introduced new bottlenecks. Engineers had to pause the automated rollback and coordinate a manual revert of all changes simultaneously.
What Amazon Changed After the Incident
Amazon's response to the incident involved changes at three levels of their deployment infrastructure.
At the AI model level, they introduced interaction modeling. Before AI-suggested changes can deploy together, the system runs a simulation modeling the combined effect against current production traffic patterns. Changes that produce unexpected interaction effects get flagged for human review.
At the deployment pipeline level, they implemented mandatory canary deployments for all AI-suggested changes. Instead of deploying AI recommendations directly to production, changes now roll out to a small percentage of traffic first. The canary phase runs for a minimum duration before the deployment can proceed, and automated metrics evaluation determines whether the canary is healthy.
At the rollback level, they switched from sequential to atomic rollback. When an AI-suggested deployment needs reverting, all changes from that batch are reverted simultaneously. This prevents the intermediate states that made the original rollback attempt worse.
Learn the guardrails every deployment pipeline needs before AI suggestions touch production infrastructure.
Read more guidesFive Guardrails Every AI-Assisted Pipeline Needs
Whether you operate at Amazon's scale or deploy a single application, these guardrails protect against AI-suggested deployment failures.
Guardrail one, canary deployments with automated evaluation. Never deploy AI-suggested changes directly to 100% of traffic. Route a small percentage (1-5%) to instances running the new configuration. Monitor error rates, latency percentiles, and resource utilization for a minimum soak period before expanding.
Guardrail two, interaction testing for simultaneous changes. If your AI tooling suggests multiple changes, test them together in a staging environment that mirrors production traffic patterns. Individual validation is necessary but not sufficient. The combined effect is what matters.
Guardrail three, atomic rollback for deployment batches. If changes were deployed together, they must be rolled back together. Sequential rollback of interdependent changes can create intermediate states that are worse than either the old or new configuration.
Guardrail four, human review for infrastructure changes. AI-suggested code changes can often be validated by automated tests. AI-suggested infrastructure changes affect networking, databases, and resource allocation in ways that automated tests rarely cover. Require a human engineer to approve any AI-suggested change that touches load balancing, connection pooling, DNS, or resource limits.
Guardrail five, blast radius limits. Configure your deployment system to limit how many services or resources an AI-suggested change can affect in a single deployment. If the AI recommends changes across ten services, deploy to one service at a time with observation periods between each. Never let an AI batch deploy across multiple critical-path services simultaneously.
Treating AI-suggested infrastructure changes like AI-suggested code changes. Code changes can be validated with tests, linters, and type checkers before deployment. Infrastructure changes affect live traffic, connection pools, and resource allocation in ways that pre-deployment tests cannot fully capture. Teams that apply the same review process to both end up with undertested infrastructure changes reaching production. AI-suggested infrastructure changes need canary deployment and production observation, not just pre-deploy validation.
The Broader Pattern in AI-Assisted Operations
Amazon's incident is not isolated. As organizations integrate AI into operational tooling, a consistent failure pattern has emerged. The AI identifies genuine optimization opportunities. Each optimization is valid in isolation. Multiple optimizations deployed together create unexpected interactions. The system enters a state that was never tested because nobody modeled the combined effect.
This pattern shows up beyond deployment. AI-driven autoscalers have triggered outages by scaling down too aggressively while shifting traffic. AI-assisted database tuning tools have caused deadlocks by optimizing query plans and connection settings simultaneously. The common thread is that AI excels at single-variable optimization but struggles with multi-variable interactions in complex systems.
The solution is not to stop using AI in deployment pipelines. The solution is to build infrastructure that treats every AI suggestion as an untested hypothesis rather than a validated recommendation. The deployment pipeline, not the AI model, is the last line of defense.
Understand how to integrate AI tooling safely into your CI/CD workflow without sacrificing deployment reliability.
Explore deployment guidesWhat This Means For You
The Amazon outage demonstrates that AI deployment failure is not a problem reserved for hyperscale companies. Any team using AI-assisted tooling to suggest or automate infrastructure changes faces the same fundamental risk. The AI optimizes locally. Your system fails globally.
- If you are a senior developer or DevOps engineer, audit your deployment pipeline this week. If AI-assisted tools can push configuration changes to production without canary deployment and human review, you have the same vulnerability Amazon had. Implement canary deployments with automated health evaluation as your first priority. Add atomic rollback as your second.
- If you are a founder or technical leader, ask your infrastructure team whether AI-suggested changes go through the same review process as human-authored changes, or whether they get a faster path to production because they "passed automated validation." If AI changes get a shortcut, that shortcut is your biggest deployment risk.
AI tools will keep improving at suggesting infrastructure optimizations. But the complexity of distributed systems means that interaction effects between changes will remain difficult to predict. The teams that build guardrails now will benefit from AI-assisted deployment safely. The teams that trust AI suggestions without verification will eventually write their own post-mortem.