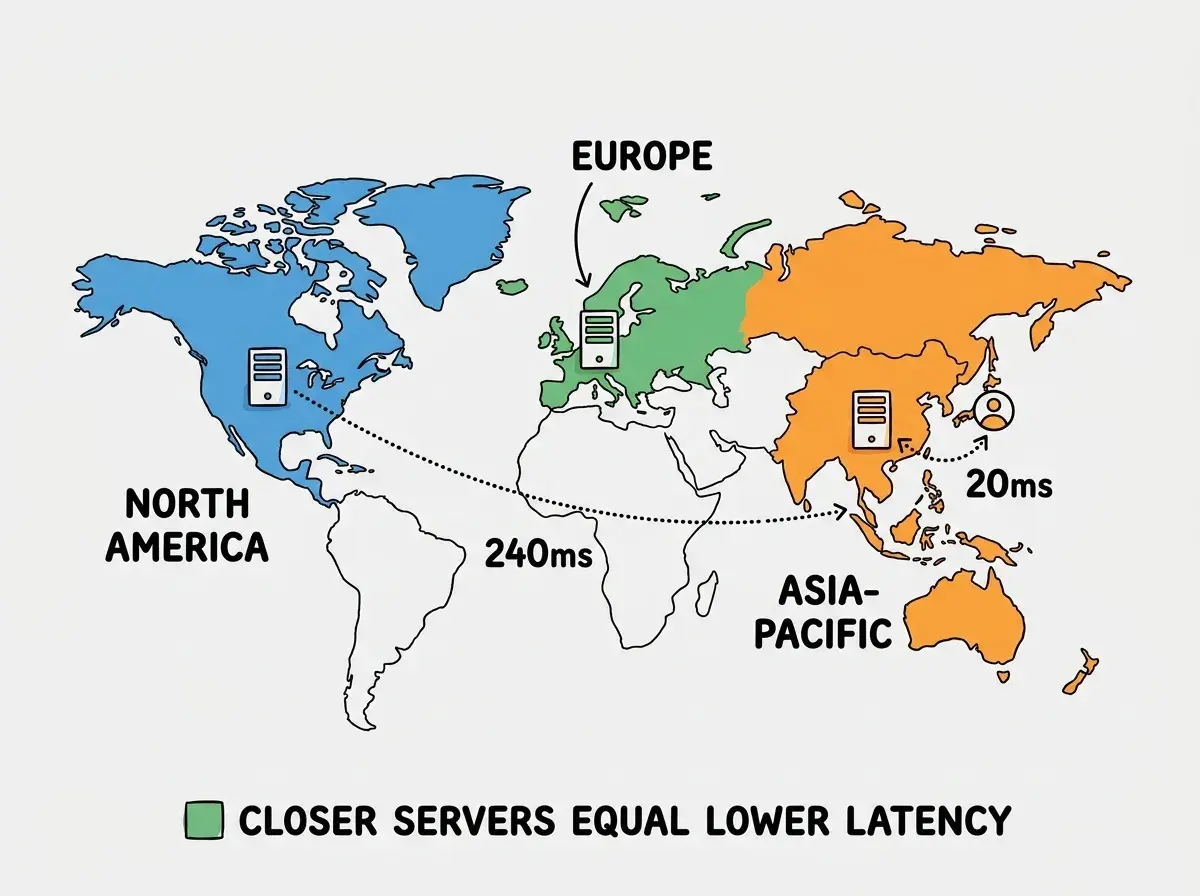
Multi-region deployment is like opening branch offices in different cities instead of making every customer travel to headquarters. When your only server sits in us-east-1 and a user in Tokyo makes a request, that request flies across the Pacific Ocean, gets processed, and flies back. That round trip adds 200 to 300 milliseconds of latency before your application logic even starts running. Open a branch office in Tokyo, and that same user gets a response in 20 milliseconds.
The analogy holds deeper than you might expect. A branch office needs local staff, local inventory, and a way to stay synchronized with headquarters. A regional deployment needs local compute, local data, and a replication strategy to keep everything consistent. The complexity is real, and most applications do not need it. But when you do need it, the performance difference is dramatic.
92% of US developers now use AI coding tools daily, and the apps they are building increasingly serve global audiences from day one. A SaaS tool, an API, a real-time collaboration app. If your users span continents, a single-region deployment is a performance ceiling you will eventually hit.
Why Latency Matters More Than You Think
Every network request between your user and your server accumulates latency. A page load that makes 15 API calls to a server 200ms away adds 3 full seconds of network time alone, assuming no parallelization. Users notice. Google's research shows that a 100ms increase in page load time reduces conversion by 1.1%. At 3 seconds of total load time, 53% of mobile users abandon the page entirely.
The physics are non-negotiable. A packet from New York to Sydney takes approximately 80ms one way through fiber, and real-world routing adds another 40 to 80ms on top. You cannot optimize your way past physics. You can only move your code closer to your users.
Edge Compute Platforms That Handle the Hard Parts
The good news is that multi-region deployment has gotten dramatically simpler. You no longer need to provision servers in six data centers. Edge compute platforms distribute your code automatically.
Cloudflare Workers run your code across 300+ locations worldwide. When a user in Berlin makes a request, it executes on a Cloudflare node in Frankfurt, not in Virginia. The deployment model is elegant: you push code once, and Cloudflare distributes it everywhere. Workers support JavaScript, TypeScript, Rust, and Python. The cold start time is under 5ms because Workers use V8 isolates instead of containers.
// A Cloudflare Worker that responds from the nearest edge location
export default {
async fetch(request: Request, env: Env): Promise<Response> {
const cf = request.cf;
const userCity = cf?.city || 'unknown';
const colo = cf?.colo || 'unknown'; // The Cloudflare data center handling this request
// Your application logic runs at the edge, not in a central server
const data = await env.KV.get(`content:${request.url}`, 'json');
return new Response(JSON.stringify({
data,
servedFrom: colo,
userLocation: userCity
}), {
headers: { 'Content-Type': 'application/json' }
});
}
};
Vercel Edge Functions offer a similar model for Next.js applications. Add export const runtime = 'edge' to any API route or page, and it runs on Vercel's edge network instead of a single-region serverless function.
// Next.js API route running at the edge
export const runtime = 'edge';
export async function GET(request: Request) {
// This executes at the edge location nearest to the user
const response = await fetch('https://api.example.com/data', {
// Next.js caches this at the edge for subsequent requests
next: { revalidate: 60 }
});
return Response.json(await response.json());
}
Fly.io takes a different approach, running full containers in regions you select, which gives you more flexibility at the cost of higher cold starts. Think of Cloudflare Workers and Vercel Edge as franchises with a standardized setup in every city. Fly.io is like opening custom offices where you control the furniture, the layout, and the staff.
Edge compute platforms eliminate the operational complexity of multi-region deployment. You do not need to manage servers in six data centers. Push your code once, and platforms like Cloudflare Workers distribute it to 300+ locations automatically. The hard part is no longer getting your compute to the edge. The hard part is getting your data there.
The Database Problem
Compute at the edge is solved. Data at the edge is where things get complicated.
Your Workers can run in 300 locations, but if every request queries a PostgreSQL database in us-east-1, you have just moved the latency problem from your application server to your database connection. The user gets a fast initial response, then waits 200ms for every database query.
There are several strategies for solving this, each with tradeoffs.
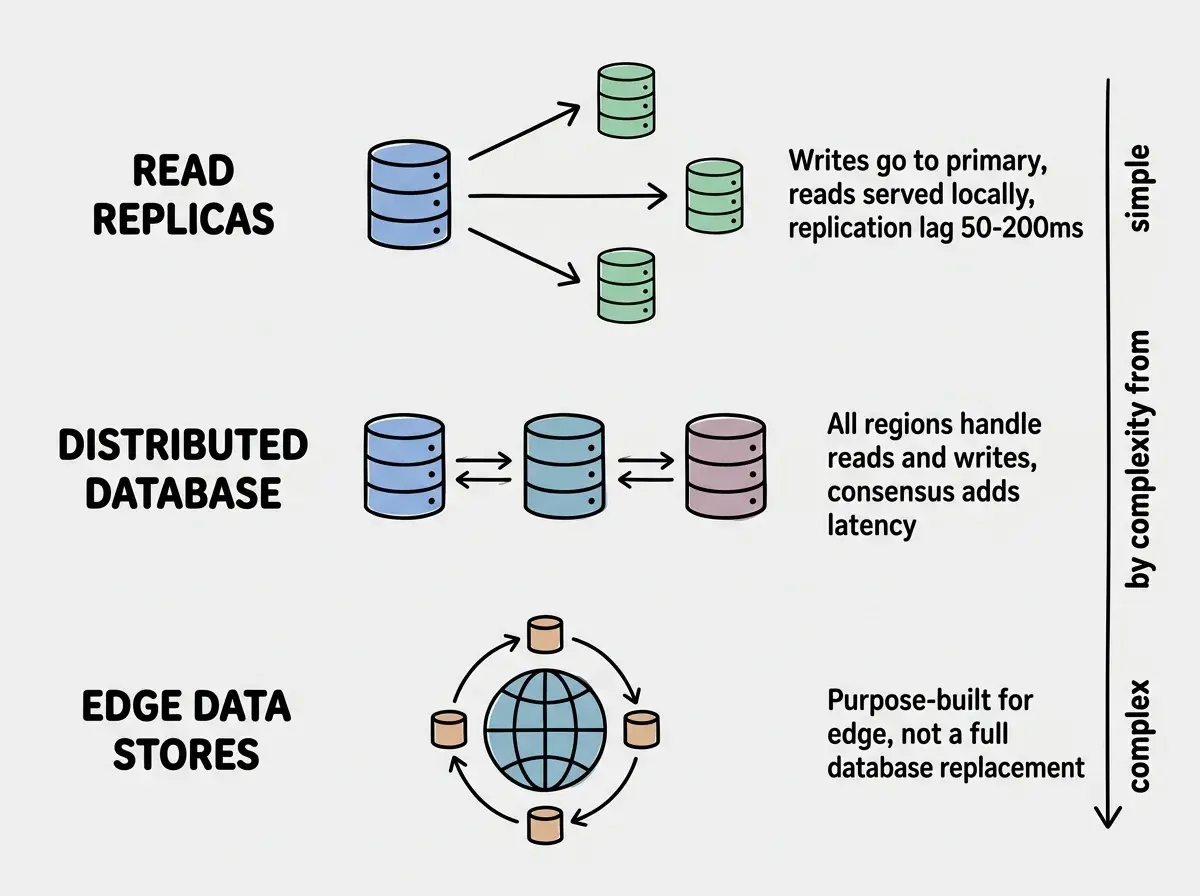
Read replicas are the most straightforward approach. Your primary database stays in one region and handles all writes. Read replicas in other regions handle read queries with low latency. Most managed database providers support this. PlanetScale, Neon, and CockroachDB all offer multi-region read replicas. The tradeoff is replication lag. A write to the primary might take 50 to 200ms to propagate to replicas. For most applications, this is acceptable.
// Routing reads to the nearest replica, writes to the primary
import { Pool } from '@neondatabase/serverless';
function getConnectionString(isWrite: boolean, region: string): string {
if (isWrite) {
return process.env.DATABASE_PRIMARY_URL!; // Always us-east-1
}
// Route reads to the nearest replica
const replicas: Record<string, string> = {
'eu': process.env.DATABASE_EU_URL!,
'ap': process.env.DATABASE_AP_URL!,
'us': process.env.DATABASE_PRIMARY_URL!,
};
return replicas[region] || replicas['us'];
}
Distributed databases like CockroachDB and Google Spanner go further. They replicate both reads and writes across regions using consensus protocols. Every region can handle writes without forwarding to a primary. The tradeoff is write latency, because achieving consensus across regions takes time. A write that takes 5ms on a single-region database might take 100ms on a globally distributed one.
Edge-native data stores like Cloudflare KV, Durable Objects, and D1 are purpose-built for edge compute. KV is eventually consistent with global read performance under 10ms. Durable Objects provide strong consistency for a single object but are pinned to one location. D1 is SQLite at the edge with read replicas. These work well for specific patterns but are not general-purpose database replacements.
Think of it this way. Your branch offices all have the latest product catalog (read replicas), but placing a new order still goes through headquarters (primary writes). That is the read replica model, and it works for 90% of applications.
A Practical Multi-Region Architecture
Here is a concrete architecture that works for most applications with a global user base. This is not theoretical. It is the pattern running behind many production apps built on Cloudflare and Vercel.
Static assets and pages are served from a CDN automatically. If you are using Next.js with static generation or ISR, your HTML pages are cached at edge locations worldwide. This is multi-region for free.
API routes and server-side rendering run on edge compute. Your server-side logic executes at the nearest edge location. For read-heavy API routes, pair this with database read replicas for full-stack edge performance.
Write operations route to your primary region. The added latency on writes is acceptable because writes are far less frequent than reads (typically a 90/10 or 95/5 read/write ratio).
Session and auth data use edge-native storage. Cloudflare KV or Vercel Edge Config stores session tokens at the edge, so authentication checks do not round-trip to a central server.
Start with the right foundation before scaling to multiple regions.
See the deployment checklistConsistency Tradeoffs You Need to Understand
The CAP theorem directly affects your multi-region architecture decisions. In the presence of a network partition (and partitions will happen between regions), you choose between consistency and availability.
Eventual consistency means a write in one region will propagate to all regions, but there is a window where different regions return different data. Cloudflare KV uses this model. If a user updates their profile in the US and immediately checks from a European edge node, they might see stale data for a few seconds. For most content and user preferences, this is fine.
Strong consistency means every read returns the most recent write, regardless of which region handles the request. This requires coordination between regions, adding latency to every operation. You need this for financial transactions, inventory counts, and anything where stale reads cause real problems.
The practical rule is to use eventual consistency everywhere you can, strong consistency only where you must. Your branch offices can work with yesterday's employee handbook, but they need real-time inventory counts.
Going multi-region before you have users in multiple regions. Multi-region deployment adds complexity to your database layer, your deployment pipeline, your debugging workflow, and your costs. If 95% of your users are in North America, a single-region deployment in us-east-1 with a CDN in front serves them perfectly. Measure your actual user geography before investing in multi-region infrastructure. The latency difference only matters when you have real users experiencing it.
When You Actually Need Multi-Region
Not every application benefits from multi-region deployment. Here is a straightforward decision framework.
You probably need it if your application serves users across three or more continents, your p95 latency exceeds 500ms and server location is the bottleneck, you have real-time features (chat, collaboration, live updates) where latency is noticeable, or your application requires high availability with regional failover.
You probably do not need it if your users are concentrated in one geographic region, your application is mostly static content (a CDN handles this already), you are pre-product-market-fit and optimizing for iteration speed, or your latency bottleneck is database queries and application logic rather than network distance.
Start with these free wins before going multi-region. Use a CDN for static assets (most hosting platforms do this automatically). Enable gzip or brotli compression. Optimize your database queries. Add appropriate cache headers. These improvements often eliminate the perceived need for multi-region deployment entirely.
The branch office analogy has a useful final lesson. You would not open offices in ten cities before proving your business model works in one. Scale your infrastructure to match your actual user base, not the user base you hope to have. Measure first. Add complexity only when measurements justify it. Your users in Tokyo will tell you (through bounce rates and session durations) whether they need a closer branch office.
Multi-region is one piece of the performance puzzle. Make sure you have the full picture.
Explore the performance guides